The Ti in TiKV stands for titanium. Titanium has the highest strength-to-density ratio of any metallic element and is named after the Titans of Greek mythology.
Concepts
Some basic facts about TiKV
TiKV is a distributed transactional key-value database originally created by PingCAP to complement TiDB.
As an incubating project of the Cloud Native Computing Foundation, TiKV is intended to fill the role of a unifying distributed storage layer. TiKV excels at working with data in the large by supporting petabyte scale deployments spanning trillions of rows.
It compliments other CNCF projects technologies like etcd which is useful for low-volume metadata storage, and can be extended using stateless query layers which speak other protocols, like TiDB speaking MySQL.
Notable Features
| Feature | Description |
|---|---|
| Low and stable latency | RawKV’s average response time less than 1 ms (P99=10 ms). |
| High scalability | With the Placement Driver and carefully designed Raft groups, TiKV excels in horizontal scalability and can easily scale to 100+ terabytes of data. Scale-out your TiKV cluster to fit the data size growth without any impact on the application. |
| Easy to use | Run a single command to deploy a TiKV cluster with everything you need for production environments. Easily scale out or scale in the cluster with TiUP or TiKV operator. |
| Easy to maintain | TiKV is based on the design of Google Spanner and HBase, but simpler to manage without dependencies on any distributed file system. |
| Consistent distributed transactions | Similar to Google’s Spanner, TiKV (TxnKV mode) supports externally consistent distributed transactions. |
| Adjustable consistency | In RawKV and TxnKV modes, you can customize the balance between consistency and performance. |
You can browse a complete list on the features page.
Architecture
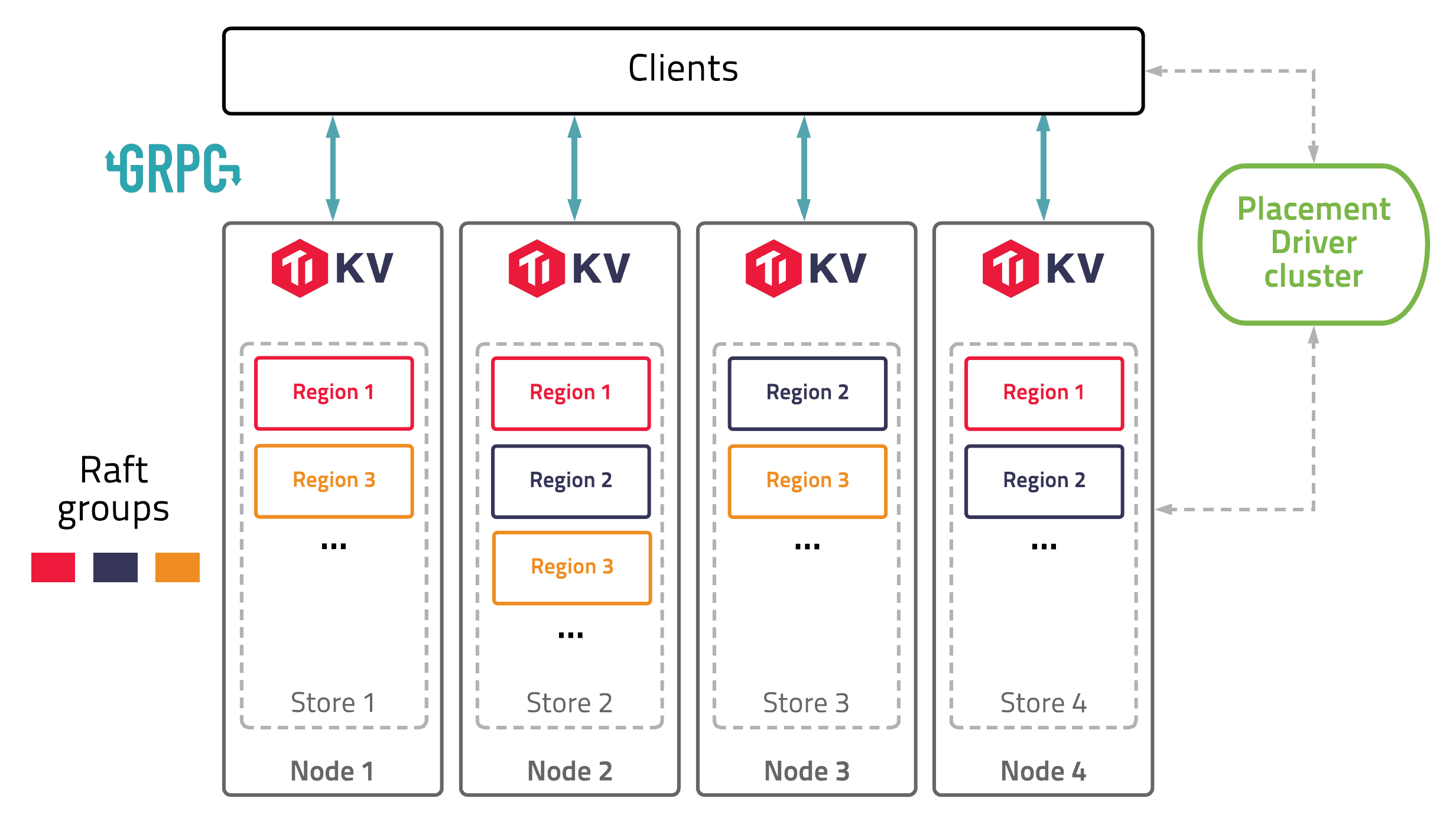
You can read more in the Concepts and architecture documentation.
Codebase, Inspiration, and Culture
TiKV is implemented in the Rust programming language. It uses technologies like Facebook’s RocksDB and Raft.
The project was originally inspired by Google Spanner and HBase.