Architecture
How TiKV works and how it was built
This page discusses the core concepts and architecture behind TiKV, including:
- The APIs that applications can use to interact with TiKV
- The basic system architecture underlying TiKV
- The anatomy of each instance in a TiKV installation
- The role of core system components, including the Placement Driver, Store, Region, and Node
- TiKV’s transaction model
- The role of the Raft consensus algorithm in TiKV
- The origins of TiKV
APIs
TiKV provides two APIs that you can use to interact with it:
| API | Description | Atomicity | Use when… |
|---|---|---|---|
| Raw | A lower-level key-value API for interacting directly with individual key-value pairs. | Single key | Your application doesn’t require distributed transactions or multi-version concurrency control (MVCC) |
| Transactional | A higher-level key-value API that provides ACID semantics | Multiple keys | Your application requires distributed transactions and/or MVCC |
System architecture
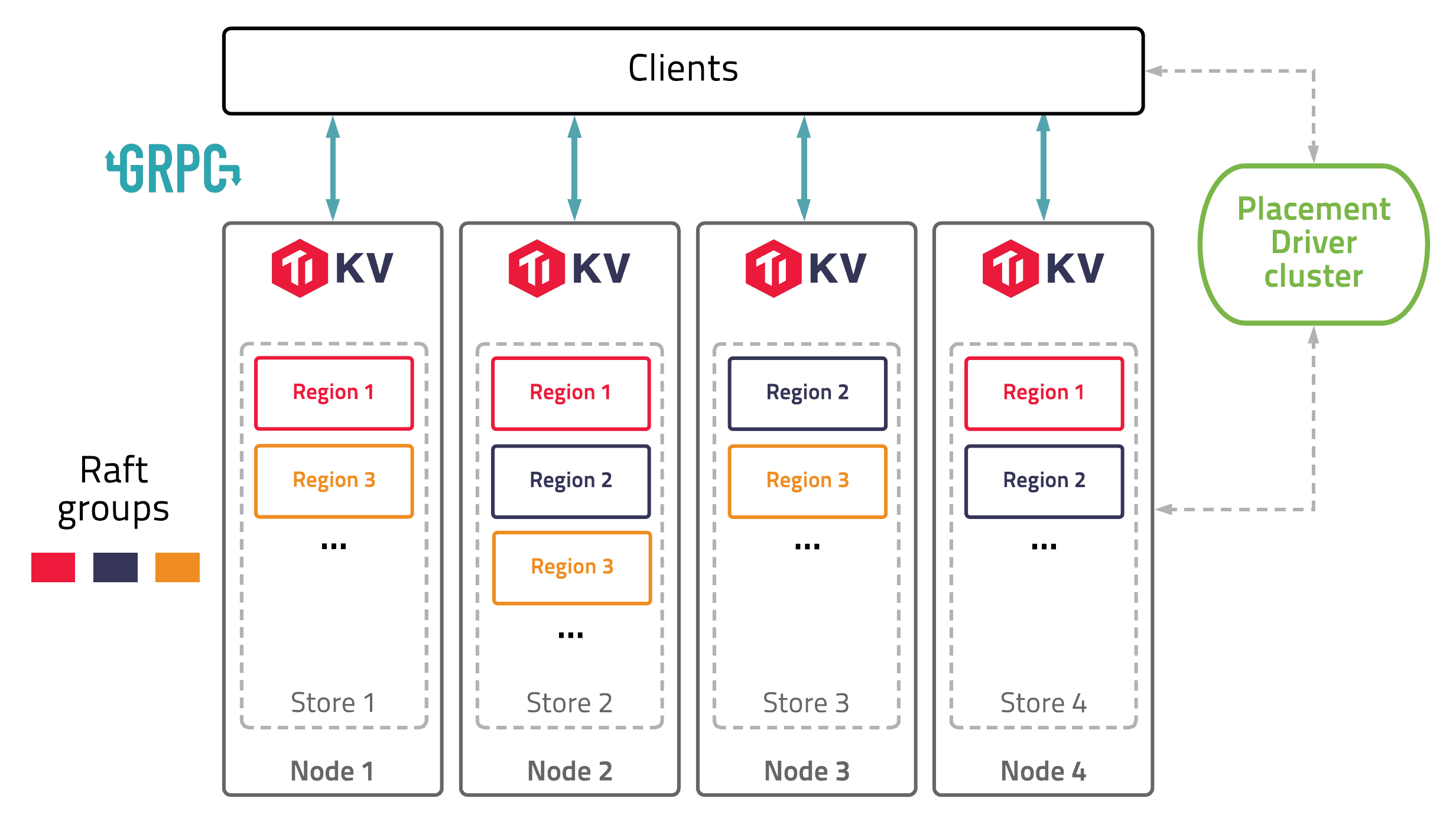
The overall architecture of TiKV is illustrated in Figure 1 below:
TiKV instance
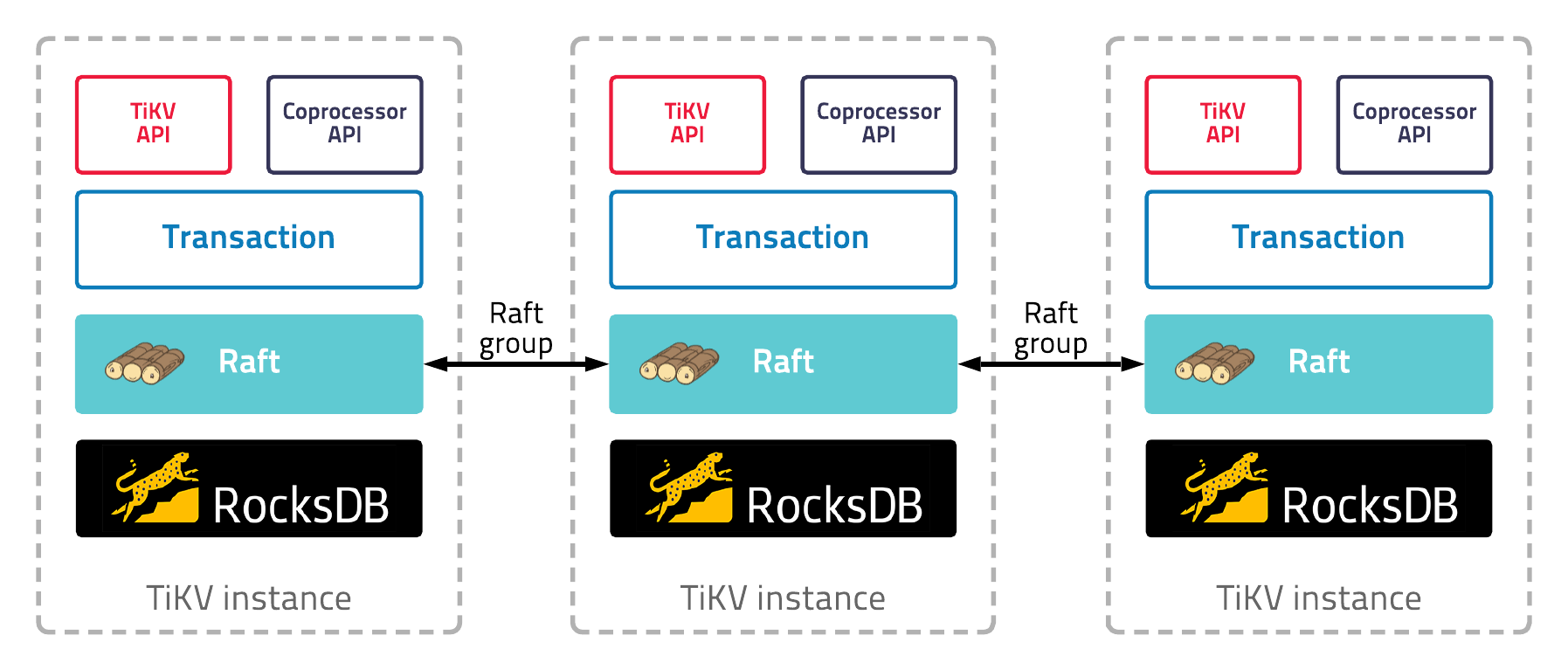
The architecture of each TiKV instance is illustrated in Figure 2 below:
Placement driver (PD)
The TiKV placement driver is the cluster manager of TiKV, which periodically checks replication constraints to balance load and data automatically across nodes and regions in a process called auto-sharding.
Store
There is a RocksDB database within each Store and it stores data into the local disk.
Region
Region is the basic unit of key-value data movement. Each Region is replicated to multiple Nodes. These multiple replicas form a Raft group.
Node
A TiKV Node is just a physical node in the cluster, which could be a virtual machine, a container, etc. Within each Node, there are one or more Stores. The data in each Store is split across multiple regions. Data is distributed across Regions using the Raft algorithm.
When a Node starts, the metadata for the Node, Store, and Region is recorded into the Placement Driver. The status of each Region and Store is regularly reported to the PD.
Transaction model
TiKV’s transaction model is similar to that of Google’s Percolator, a system built for processing updates to large data sets. Percolator uses an incremental update model in place of a batch-based model.
TiKV’s transaction model provides:
- Snapshot isolation with lock, with semantics analogous to
SELECT ... FOR UPDATEin SQL - Externally consistent reads and writes in distributed transactions
Raft
Data is distributed across TiKV instances via the Raft consensus algorithm, which is based on the so-called Raft paper (“In Search of an Understandable Consensus Algorithm”) from Diego Ongaro and John Ousterhout.
The origins of TiKV
TiKV was originally created by PingCAP to complement TiDB, a distributed HTAP database compatible with the MySQL protocol.