Multi-raft
If you’ve researched Consensus before, please note that comparing Multi-Raft to Raft is not at all like comparing Multi-Paxos to Paxos. Here Multi-Raft only means we manage multiple Raft consensus groups on one node. From the above section, we know that there are multiple different partitions on each node, if there is only one Raft group for each node, the partitions losing its meaning. So Raft group is divided into multiple Raft groups in terms of partitions, namely, Region.
TiKV also can perform split or merge on Regions to make the partitions more flexible. When the size of a Region exceeds the limit, it will be divided into two or more Regions, and the range may change like \( [a, c) \) -> \( [a, b) \) + \( [b, c) \); when the sizes of two sibling Regions are small enough, they will be merged into a bigger Region, and the range may change like \( [a, b) \) + \( [b, c) \) -> \( [a, c) \).
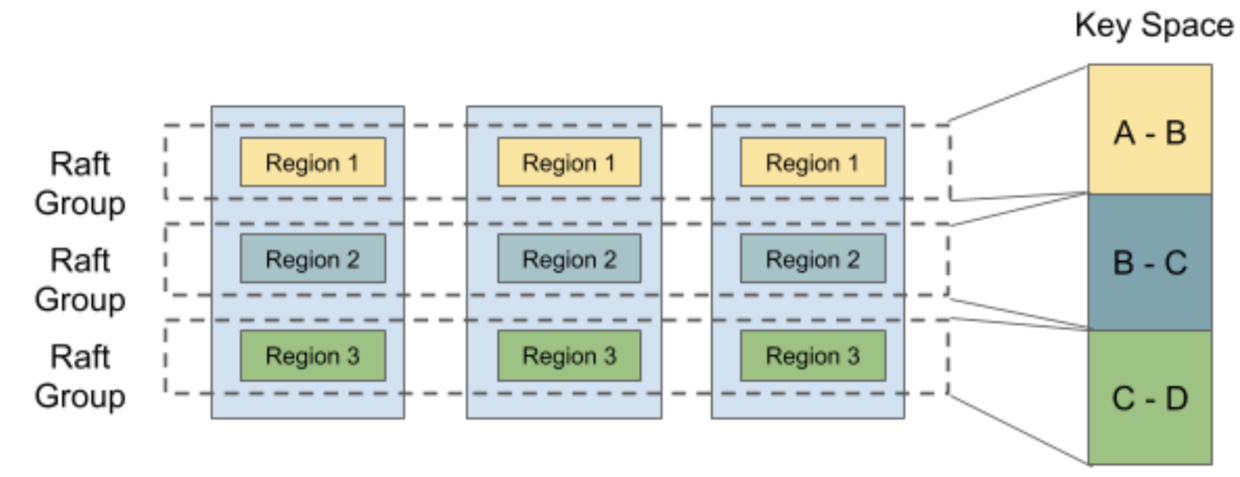
For each Raft group, the process of the algorithm is still as before, and we only introduce a layer on top of Raft to manage these Raft consensus groups as a whole.
TiKV uses an event loop to drive all the processes in a batch manner. It polls all the Raft groups to drive the Raft state machine every 1000ms and accepts the requests from the outside clients and Raft messages sent by other nodes through the notification mechanism of the event loop.
For each event loop tick, it handles the Raft ready of each Raft group:
- It traverses all the ready groups and uses a RocksDB’s
WriteBatchto handle all appending data and persist the corresponding result at the same time. - If
WriteBatchsucceeds, it then sends messages of every Raft group to corresponding Followers. TiKV reuses the connection between two nodes for multiple Raft groups. - Then it applies any committed entries and executes them.