This is the speech presented by Liu (Siddon) Tang at the RocksDB meetup on August 28, 2017. Some of the content has been adapted to be up to date.
- Speaker Introduction
- Why did we choose RocksDB?
- How are we using RocksDB?
- How are we contributing?
- Future Plans
Speaker Introduction
Hi everyone, thanks for having me here, the RocksDB team.
Today, I will talk about how we use RocksDB in TiKV. Before we start, I will introduce myself briefly. My name is Siddon Tang, chief engineer at PingCAP. Now I am working on TiDB, the next generation SQL database; and TiKV, a distributed transactional key-value store. I am an open source lover and I have developed some open source projects like LedisDB (BTW, the backend engine is also RocksDB), go-mysql, go-mysql-elasticsearch, etc…
Why did we choose RocksDB?
OK, let’s begin. Why did we decide to use RocksDB instead of LevelDB, WiredTiger, or any other engines? Why? I have a long list of reasons:
- First of all, RocksDB is fast. We can keep high write/read speed even there’s a lot of data in a single instance.
- And of course, RocksDB is stable. I know that RocksDB team does lots of stress tests to guarantee the stability;
- And it’s easy to be embedded. We can call RocksDB’s C API in Rust directly through FFI, because TiKV is written in Rust.
- Not to mention that it has many useful features. We can use them directly in production to improve the performance.
- In addition, RocksDB is still in fast development. Many cool features are added, and the performance is being improved continuously.
- What’s more, RocksDB has a very active community. If we have questions, we can easily ask for help. Many RocksDB team members and we are even WeChat (a very popular IM tool in China) friends, we can talk to each other directly.
How are we using RocksDB?
TiKV Architecture
After we decided to use RocksDB, the next question is how to use it in TiKV. Let me start with the TiKV architecture briefly.
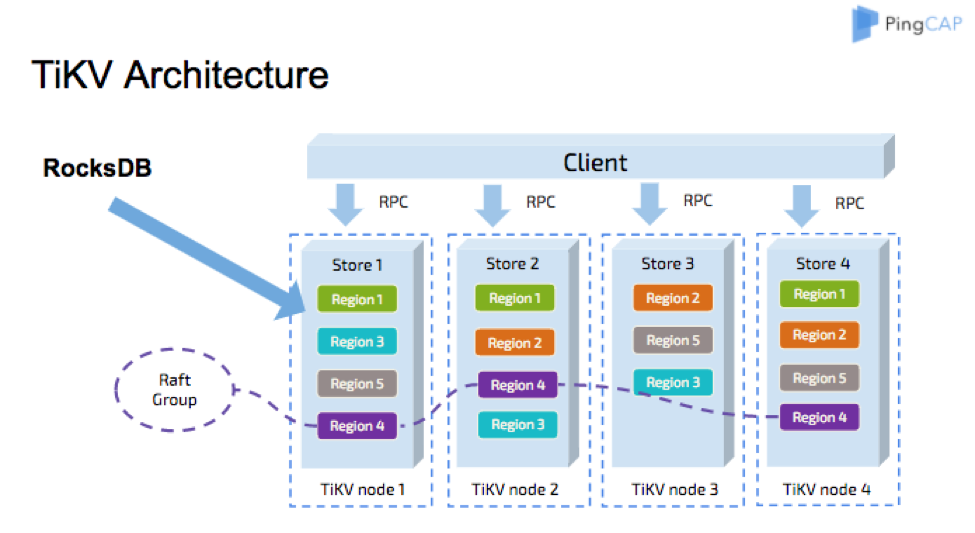
First of all, all data in a TiKV node shares two RocksDB instances. One is for data, and the other is for Raft log.
Region
Region is a logical concept: it covers a range of data. Each region has several replicas, residing on multiple machines. All these replicas form a Raft group.
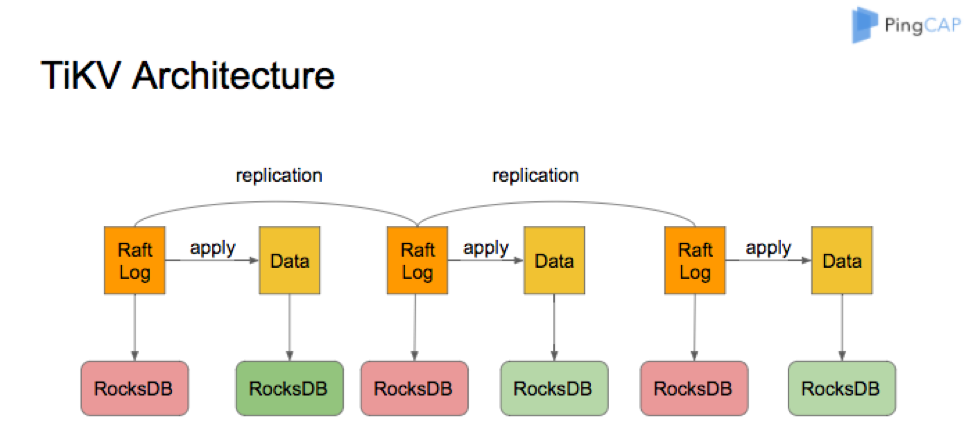
Raft
TiKV uses the Raft consensus algorithm to replicate data, so for every write request, we will first write the request to the Raft log, after the log is committed, we will apply the Raft log and write the data.
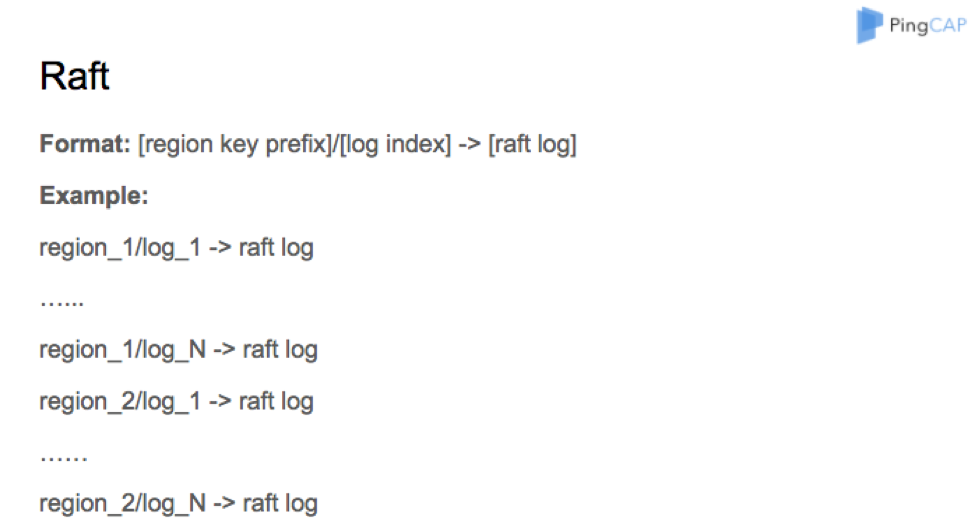
The key format for our Raft log saved in RocksDB is region ID plus log ID, and the log ID is monotonically increased.
InsertWithHint

We will append every new Raft log to the region. For example, we first append log 1 for region 1, then we might append log 2 for the same region later. So we use memtable insert with the hint feature, and this feature improves the insert performance by fifteen percent at least.
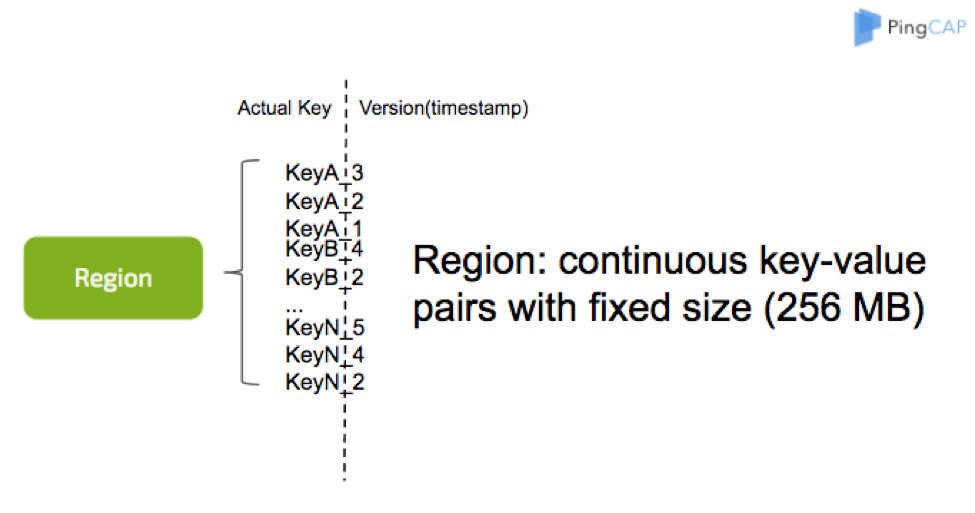
The version is embedded in the key as a suffix, and used for ACID transaction support. But transaction management is not our topic today, so I just skip it.
Prefix Iterator

As you can see, we save the key with a timestamp suffix, but can only seek the key without the timestamp, so we set a prefix extractor and enable the memtable bloom filter, which helps us improve the read performance by ten percent at least.
Table Property for Region Split Check
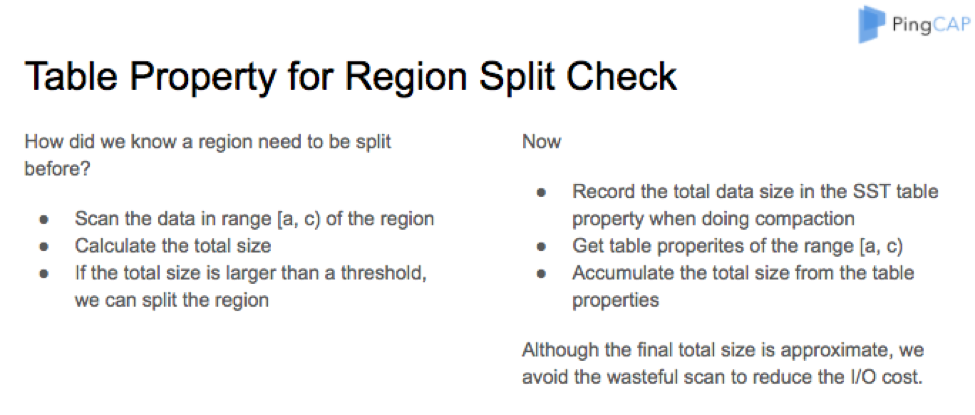
If we insert a lot of data into a region, the data size will soon exceed the threshold which we predifine and need to be split.
In our previous implementation, we must first scan the data in the range of the region, then calculate the total size of the data, if the total size is larger than the threshold, we split the region.
Scanning a region has a high I/O cost, so now, we use table properties instead. We record the total data size in the SST table property when doing compaction, get all table properties in the range, then add up the total size.
Although the final calculated total size is approximate, it is more effective, we can avoid the useless scan to reduce the I/O cost.
Table Property for GC Check

We use multiple versions for a key, and will remove the old keys periodically. But we don’t know whether we need to do GC in a range or not. In the past, we simply scanned all the data.
However, since we only need to do GC before a specified safe point, and most keys have only one version, scanning these keys every time is wasteful.
So we create an MVCC property collector to collect the version information, including the maximum and minimum timestamp, the row number and version number. Then every time before scanning a range, we can check these properties to see if we can skip the GC procedure or not.
For example, if we find the minimal timestamp in the table property is bigger than the safe point, we can immediately skip scanning the range.
Ingest the SST File
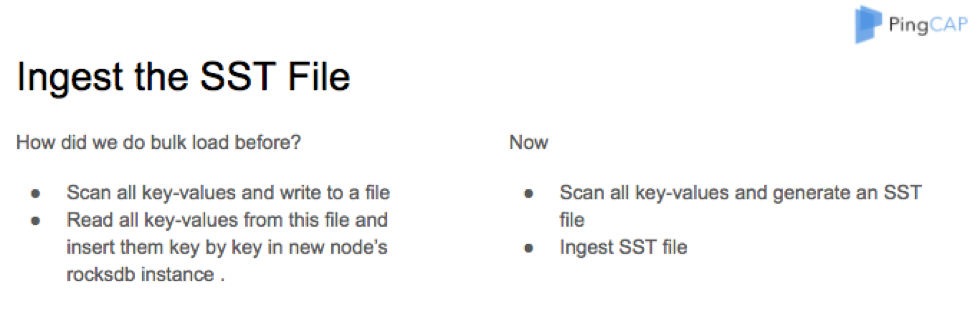
And in our previous implementation, if we wanted to do bulk load, we must scan all the key-values in the range and save them into a file. Then in another RocksDB, read all the key-values from this file and inserted them in batches.
As you can see, this flow is very slow and can cause high pressure in RocksDB. So now, we use the IngestFile feature instead. At first, we scan the key-values and save them to an SST file, then we ingest the SST file directly.
Others

More than that, we enable sub compaction, pipelined write, and use direct I/O for compaction and flush. These cool features also help to improve the performance.
How are we contributing?
We are not only using RocksDB, we also do our best to contribute back to the community. We have done many stress tests and have found some serious data corruption bugs, like these issues:
- #1339: sync write + WAL may still lose newest data
- #2722: some deleted keys might appear after compaction
- #2743: delete range and memtable prefix bloom filter bug
Thank goodness, we haven’t found any of our users meet these problems in production.
We also added features and fixed some bugs, like these. Because TiKV can only call the RocksDB C API, we also add many missing C APIs for RocksDB.
- #2170: support PopSavePoint for WriteBatch
- #2463: fix coredump when release nullptr
- #2552: cmake, support more compression type
- many C APIs
We keep contributing to the RocksDB community by reporting issues, adding features and fixing bugs. In 2019, we opened 11 issues and contributed 24 PRs to the RocksDB project, and would love to keep it up.
Future Plans
We have built Titan, a RocksDB Plugin for key-value separation, which has been proven to be very useful to reduce write amplification in RocksDB when writing large values. We have plans to contribute Titan to RocksDB in the future. Besides, we will also try different memtable types to speed up the insert performance, and use partitioned indexes and filters for SATA disks.