Consensus is one of the most important challenges in designing and building distributed systems–how to make sure multiple nodes (or agents, processes, threads, tasks, participants, etc.) in a group agree on a specific value proposed by at least one of the nodes. As an open-source distributed transactional key-value database, TiKV uses the Raft Consensus Algorithm to ensure data consistency, auto-failover, and fault tolerance. TiKV has thus far been used by almost 1000 adopters in their production environments in a wide range of industries, from e-commerce and food delivery, to fintech, media, gaming, and travel.
Ever since the Raft Consensus Algorithm was created by Diego Ongaro and John Ousterhout, it has gained wide popularity in many organizations, who are using it to develop consistent distributed services with high availability. For example, CoreOS uses it to build etcd, a popular key-value store which helps users save critical data. HashiCorp uses it to build Consul, which helps make service discovery and configuration easy.
When we began to build TiKV, we researched and investigated many Raft implementations. We eventually decided to go with etcd’s Raft implementation and built our own Raft using Rust, a systems programming language that runs blazing fast, prevents segfaults, and guarantees thread safety. Although etcd’s Raft implementation is written in Go, it has a simple API with no specific Go feature, thus can be easily ported to Rust.
Since TiKV was open sourced on April 1, 2016, its Raft module has been running stably in many companies’ production environment. So we decided to abstract the Raft module away as an independent library and released it as a crate, raft-rs, to help the Rust community create their own consistent services using this easy to understand consensus algorithm. In the following sections, I will introduce what is raft-rs and how to use it.
Design
In this post, I won’t cover the ins-and-outs of the Raft algorithm in detail, since there are many good resources that already cover that topic. Before we dive into raft-rs, let’s walk through its design first.
As you probably already know, Raft replicates the state machine through logs. If we can ensure all the machines have the same sequence of logs, after applying all logs in order, the state machine will reach a consistent state.
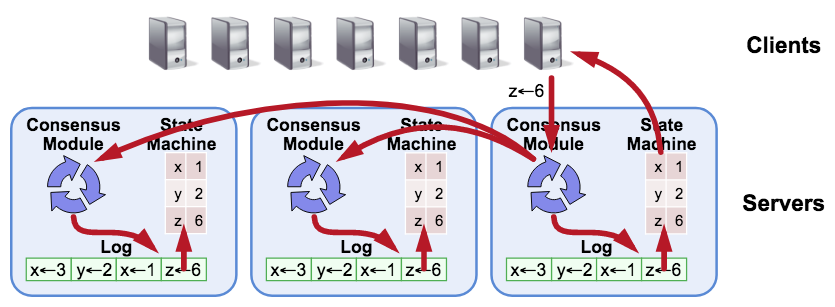
A complete Raft model contains 4 essential parts:
- Consensus Module, the core consensus algorithm module;
- Log, the place to keep the Raft logs;
- State Machine, the place to save the user data;
- Transport, the network layer for communication.
Our raft-rs implementation includes the core Consensus Module only, not the other parts. The core Consensus Module in raft-rs is customizable, flexible, and resilient. You can directly use raft-rs, but you will need to build your own Log, State Machine and Transport components.
How to use raft-rs
In this section, I will show you how to use raft-rs. Please note that we will only cover the Raft Log as it pertains to the Consensus Module, not how to apply the Log to the State Machine or Transport the messages from one node to another.
Step 1: Create the Raft node
You can use RawNode::new() to create the Raft node. To create the Raft node, you need to build a Log component, which is called Raft Storage in raft-rs, and then configure the Raft node.
- Build Raft Storage
Raft Storage saves all the information about the current Raft implementation, including Raft Log, commit index, the leader to vote for, etc.
Storage is a trait defined in storage.rs. Here is the trait interface in detail:
initial_stateis called when Raft is initialized. This interface will return aRaftStatewhich containsHardStateandConfState;HardStatecontains the last meta information including commit index, the vote leader, and the vote term;ConfStaterecords the current node IDs like[1, 2, 3]in the cluster. Every Raft node must have a unique ID in the cluster;
entriesreturns the Log entries in an interval[low, high);termreturns the term of the entry at Log index;first_indexandlast_indexreturn the first and last index of the Log;
These interfaces are straightforward to understand and implement, but you should pay attention to what is returned when there is no Log but needs to get the term at index first_index() - 1. To solve this, we usually use a dummy Log entry to keep the last truncated Log entry.
- The last interface is
snapshot, which returns a Snapshot of the current state machine. We will send this Snapshot data to another node.
- Configure the Raft node
After we create the Raft Storage, the next step is to use RawNode::new() to create the Raft node. The new function needs a Raft Storage and a configuration. There are some important fields for this configuration:
id: the unique ID of the node in the cluster, which must be unique;election_tick: how many ticks the follower re-campaigns if it doesn’t receive any message from the leader;heartbeat_tick: how many ticks the leader sends the heartbeat to the followers to keep alive;applied: the last applied index for the state machine. Raft will resume applying Log entries to the state machine from this index;max_size_per_msg: Raft can send many Log entries at the same time, so we need to limit the maximum size of the sending message. This is an optimization for Transport in batch;max_inflight_msgs: how many messages the leader can send to the followers without acknowledgement. This is an optimization for the Transport in pipeline.election_tickmust be larger thanheartbeat_tick. If our tick interval is 100 ms, we can use 10 forelection_tickand 3 forheartbeat_tick, which means the leader will send heartbeat to the followers every 300 ms and the follower will re-campaign without receiving any messages after 1 second.- The
read_only_optionenables you to choose the linearizability mode or the lease mode to read data. If you don’t care about the read consistency and want a higher read performance, you can use the lease mode.
Other important fields like check_quorum and pre_vote are used to avoid the disturbance and make the cluster more stable. I will explain them in detail in another article later.
Step 2: Drive and Run the Raft node
Now that you have created a Raft node, the next step is to drive and run the Raft node. Here is an example ported from raft-rs/examples:
let mut tick_timeout = Duration::from_mills(100);
let start_tick = Instant::now();
loop {
loop {
// Step raft messages.
match receiver.recv_timeout(tick_timeout) {
Ok(msg_or_command) => {
match msg_or_command {
RaftMessage(msg) => raft.step(msg),
RaftCommand { proposal, callback } => {
// Save the proposal ID and its associated callback.
context.insert(proposal.get_id(), callback);
raft.propose(proposal);
}
}
tick_timeout -= start_tick.elapsed();
break;
}
Err(RecvTimeoutError::Timeout) => {
// Tick the raft.
start_tick = Instant::now();
tick_timeout = Duration::from_mills(100);
raft.tick();
break;
}
Err(RecvTimeoutError::Disconnected) => return,
}
}
if raft.has_ready() {
// Handle readies from the raft.
handle_raft_ready(raft.ready());
}
}
There are three steps to this process before handle_raft_ready:
You can call the
stepfunction when you receive the Raft messages from other nodes.
CallingRaft::stepwill change the memory state ofRaft.Use the
proposefunction to drive the Raft node when the client sends a request to the Raft server. You can callproposeto add the request to the Raft log explicitly.
In most cases, the client needs to wait for a response for the request. For example, if the client writes a value to a key and wants to know whether the write succeeds or not, but the write flow is asynchronous in Raft, so the write log entry must be replicated to other followers, then committed and at last applied to the state machine, so here we need a way to notify the client after the write is finished.
One simple way is to use a unique ID for the client request, and save the associated callback function in a hash map. When the log entry is applied, we can get the ID from the decoded entry, call the corresponding callback, and notify the client.You need a timer to run the Raft node regularly. In the above example, we used Rust channel
recv_timeout.
As is shown in the above example, the Raft node is driven to run every 100 ms set by thetickfunction.
In the above example, we use a channel to receive the propose and step messages. We only propose the request ID to the Raft log. In your own practice, you can embed the ID in your request and propose the encoded binary request data.
Step 3: Process the Ready State
When your Raft node is driven and run, Raft may enter a Ready state. You need to first use has_ready to check whether Raft is ready. If yes, use the ready function to get a Ready state. The Ready state contains many information, and you need to check and process them one by one:
- Check whether
snapshotis empty or not. If not empty, it means that the Raft node has received a Raft snapshot from the leader and we must apply the snapshot. - Check whether
entriesis empty or not. If not empty, it means that there are newly added entries but has not been committed yet, we must append the entries to the Raft log. - Check whether
hsis empty or not. If not empty, it means that theHardStateof the node has changed. For example, the node may vote for a new leader, or the commit index has been increased. We must persist the changedHardState. - Check whether
messagesis empty or not. If not, it means that the node will send messages to other nodes. There has been an optimization for sending messages: if the node is leader, this can be done together with step 1 in parallel. - Check whether
committed_entiresis empty or not. If not, it means that there are some newly committed log entries which you must apply to the state machine. Of course, after applying, you need to update the applied index and resumeapplylater. - Call
advanceto prepare for the nextReadystate.
Try it for yourself!
As you can see, it is easy to use raft-rs. You can build your own components and combine them together to have a fully functioning Raft implementation!
As a distributed transactional key-value database that is strongly consistent, TiKV needs to go beyond a single Raft implementation. In TiKV, data is sharded into Regions, a continuous range of data in byte order. Region is the basic unit of data movement and is replicated to several nodes, which makes up a Raft group. One node in the TiKV cluster might be working with multiple Raft groups. so we designed and implemented Multi-Raft. For more details, feel free to check out “Multi-Raft Design and Implementation in TiKV.”
If you are interested in Raft and Rust, and want to build your own consistent service using raft-rs, please let me know (tl@pingcap.com). I would be thrilled to hear from you!